[Brief Review] Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion Models
Takeaway Summary
Keywords: memorization neuron, localization of neuron, memorization strength, SSIM, activation patterns of neurons, deactivation of neurons, cross-attention, text-to-image, diffusion models, noise prediction, out-of-distribution (OOD) activation, quantifying memorization, memorization metric, generation diversity
✅ Quantifying memorization strength: NeMo first establishes a numerical measure of memorization by examining whether the model’s early, seed-dependent noise predictions show consistent patterns—a sign the model may be reproducing memorized content. Specifically, SSIM (Structural Similarity Index Measure) is used to compare the initial denoising steps across different seeds, serving as a proxy for measuring memorization strength.
✅ Localizing memorization neurons: For samples deemed memorized, NeMo constructs a candidate neuron set by analyzing activation patterns between neurons involved in memorizing specific prompts and those uninvolved. It identifies candidate memorization neurons based on out-of-distribution (OOD) activations. To confirm these neurons truly cause memorization, NeMo systematically reactivates them to check if memorization reappears. Neurons that fail to restore memorization are filtered out as false positives.
✅ Key Experimental Findings:
- Memorization predominantly occurs within the value mappings of cross-attention layers in diffusion models.
- Most training samples are memorized by only a few neurons, sometimes even a single neuron.
- Deactivating memorization neurons enhances image diversity.
- The distribution of memorization neurons across layers can vary depending on the dataset.
- Memorization neurons generally exert minimal influence on prompts that are not memorized.
Brief Review
Overview
Summary: In text-to-image generative models, mitigating the impact of sensitive data is crucial for practical deployment. Localizing specific neurons responsible for memorizing sensitive information can play a pivotal role in protecting such data. NeMo is designed to localize and remove memorization within diffusion models; it is the first method to pinpoint individual neurons responsible for memorization directly within the model.
NeMo is gradient-free and does not require modifying or excluding input data, making it applicable without cumbersome environment setups or additional safeguards. This approach is both memory-efficient and straightforward to adopt.
NeMo’s workflow is divided into two parts:
- Localization:
- Quantifying Memorization: NeMo establishes a numerical measure by checking whether the model’s early, seed-dependent noise predictions follow a consistent pattern—a sign the model is reproducing memorized content. Specifically, it measures the similarity between the first denoising steps (across different seeds) to gauge memorization strength.
- Identifying Candidate Neurons: It then isolates a set of neurons whose activations deviate significantly (out-of-distribution) for memorized prompts, marking them as “candidate memorization neurons.”
- Refining the Candidates: NeMo filters out false positives by systematically reactivating these neurons to see if memorization reappears.
- Memorization Removal:
- Once the true memorization neurons are pinpointed, they can be deactivated to mitigate memorization.
Key Experimental Findings include:
- Most memorization occurs in the value mappings of cross-attention layers.
- A few neurons—or even a single neuron—can memorize entire training samples.
- Deactivating memorization neurons increases the diversity of generated images.
- The distribution of memorization neurons may vary by dataset.
- Memorization neurons have little impact on non-memorized prompts.
Finally, NeMo opens new avenues for future applications, such as concept neuron detection, memorization mitigation for sensitive data, extension to large language models (LLMs), and enhanced pruning strategies—all supported by its memory-efficient and easily adoptable design.
- Task: Localizing the memorization of data samples within neurons of cross-attention layers in Diffusion Models (DMs).
- Goal: Mitigate privacy and intellectual property infringement issues in DMs by deactivating specific neurons responsible for memorizing sensitive or copyrighted data.
- Existing Problems:
- DMs carry a significant risk to privacy and intellectual property, as the models have been shown to generate verbatim copies of their potentially sensitive or copyrighted training data at inference time.
- Prior Approaches & Limitations:
- Prior Approaches:
- Modifying inputs during inference to prevent diffusion models from producing memorized samples.
- Completely excluding memorized data from the training set.
- Adjusting the text embeddings by a gradient-based method
- Limitations:
- These methods require secure environments with continuous monitoring for effective development and deployment.
- Once diffusion models are publicly released, adversaries may circumvent safeguards, reducing their effectiveness.
- Gradient-based mitigation strategies are memory intensive.
- Prior Approaches:
- Contributions:
- Propose \(\text{NeMo}\) , the first method capable of localizing memorization within diffusion models down to individual neurons.
- Demonstrate through extensive empirical evaluations that memorization in Stable Diffusion is concentrated in only a few—or even single—neurons.
- Enable control of memorization in diffusion models by selectively deactivating neurons exhibiting strong memorization behavior.
- Show that deactivating highly memorizing neurons leads to more diverse generated outputs.
- Important Findings Regarding Memorization of Neurons
- Most memorization occurs in the value mappings of the cross-attention layers of DMs.
- Most training data samples are memorized by just a few or even a single neuron.
- Deactivating the memorization neurons results in the generation of more diverse images.
- How memorization neurons are distributed across layers might differ based on the dataset.
- Memorization neurons hardly influence non-memorized prompts.
- Potential future applications
- Concept Neuron Detection:
- An adapted version of NeMo might find concept neurons—those behind generating specific concepts (e.g., violence, nudity). This would allow knowledge editing of the model, removing or moderating certain concepts without retraining from scratch.
- Memorization Mitigation to Handle Sensitive Data:
- Because NeMo locates the specific neurons responsible for memorization, it allows model providers to remove or deactivate those neurons directly. This could become a standard practice for protecting privacy and copyright by preventing the model from reproducing sensitive training data.
- Extension to Large Language Models (LLMs):
- Applying NeMo’s neuron-localization approach could help identify and remove text‐memorizing neurons in LLMs, yielding new ways to protect sensitive text data.
- Enhanced Pruning Strategies:
- NeMo’s insights about which neurons are “memorization‐critical” could inform more advanced pruning algorithms that reduce parameter counts while ensuring no undesired memorization remains—and without harming overall performance.
- Concept Neuron Detection:
Background
The role of the cross-attention
: It is the only route through which the text prompt is involved.
Cross-attention for text-to-image DMs:
\[\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d}} \right) \cdot V\]- \(z_t\) : hidden image representation
- \(y\) : text embeddings
- \(Q = z_tW_Q\) : query matrices
- \(K = yW_k\) : key matrices
- \(V = yW_V\) : value matrices
- \(d\) : scaling factor
In a typical text-to-image diffusion model (like Stable Diffusion), all the textual information that steers image generation flows only through the cross‐attention blocks—so if the model is ever going to copy something it saw in training when given a specific text prompt, it usually happens there. Since the cross-attention layers are the only route by which the text prompt can influence the denoising process, these layers naturally become the prime location where memorization (i.e., copying from training) can occur.
Methods

Process of NeMo
- Localization
- Initial Selection: identify a wide range of neuron candidates suspected of memorizing specific training samples.
- Employs a coarse-level analysis to enhance computational efficiency.
- May include incorrectly identified neurons (false positives).
- Refinement: Narrow down the candidate set by removing irrelevant neurons.
- Initial Selection: identify a wide range of neuron candidates suspected of memorizing specific training samples.
- Memorization Removal
- After the refinement step of localization, deactivate the remaining memorization neurons to eliminate memorization.
Quantifying the Memorization Strength
Establish a numerical measure of memorization by checking whether the model’s early, seed‐dependent noise predictions reveal a consistent pattern—an indicator that the model is about to reproduce something it memorized.

- Idea: Identifying Memorization via Consistency in Reconstruction Trajectories
- For prompts that the model has memorized (i.e., those likely to reproduce near‐verbatim training data), the early noise predictions tend to follow nearly the same denoising path from one random seed to another. In contrast, non‐memorized prompts show more variation in those initial denoising steps.
- Method: Measuring the similarity between the fist denoising steps for different initial seeds as a proxy to compare the denoising trajectories and to quantify the memorization strength.
- Computing Noise Difference ( \(\delta\) )
- The authors compute the difference between the initial noise ( \(x_T\) ) and the model’s first noise prediction ( \(\epsilon_\theta(x_T, T, y)\) ). This difference, denoted \(\delta\) , captures how the model is “correcting” the initial random noise given the prompt.
Measureing the similarity between the noise differences \(\delta^{(i)}\) and \(\delta^{(j)}\) generated with seeds \(i\) and \(j\) as a proxy via SSIM.
\[\mathrm{SSIM}(\delta^{(i)}, \delta^{(j)}) = \frac{(2\,\mu_i\,\mu_j + C_1)\,\bigl(2\,\sigma_{ij} + C_2\bigr)} {\bigl(\mu_i^2 + \mu_j^2 + C_1\bigr)\,\bigl(\sigma_i^2 + \sigma_j^2 + C_2\bigr)}\]- \(\delta^{(i)}\) and \(\delta^{(j)}\) are the noise differences (e.g., from two different random seeds).
- \(\mu_i\) , \(\mu_j\) are the mean values of \(\delta^{(i)}\) , \(\delta^{(j)}\) .
- \(\sigma_i^2\) , \(\sigma_j^2\) are the variances.
- \(\sigma_{ij}\) is the covariance.
- \(C_1\) , \(C_2\) are small constants for numerical stability.
The SSIM score lies between \(0\) and \(1\) , with a higher value indicating greater similarity. In this paper, a high SSIM among noise differences for a given prompt signals that the model is likely reproducing a memorized image rather than generating new variations.
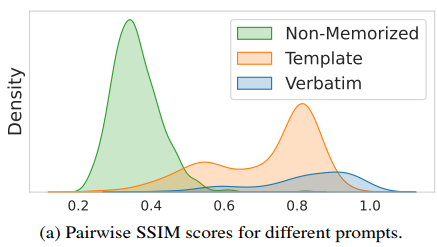
- Thresholding: By looking at the SSIM scores for multiple prompts, they define a “memorization threshold” \(\tau_{\text{mem}}\) . Prompts whose SSIM scores exceed this threshold (i.e., very high consistency across seeds) are labeled as memorized.
- Computing Noise Difference ( \(\delta\) )
Initial Candidate Section for Memorization Neurons
Build a candidate neuron set that potentially encodes memorization by examining activation differences between neurons involved in memorizing specific prompts and those uninvolved.
Idea: Activation patterns of memorized prompts differ from the ones of non-memorized prompts on the neuron level.
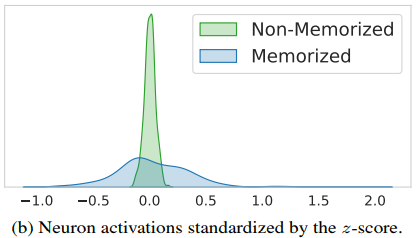
Method: Selecting candidate memorization neurons based on whether they exhibit out-of-distribution (OOD) activation behavior.
- Precompute mean \(\mu_i\) & variance \(\sigma_i\) for each neuron
- Identify OOD neurons via \(z\) ‐scores
For a memorized prompt \(y\) , measure each neuron’s standardized activation:
\[z_i^l(y) = \frac{a_i^l(y) - \mu_i^l}{\sigma_i^l}\]where:
- \(a_i^l(y)\) is the activation value of neuron \(i\) for prompt \(y\) .
- \(\mu_i^l\) is the mean activation of neuron \(i\) , usually computed over non-memorized prompts or a baseline set.
- \(\sigma_i^l\) is the standard deviation of neuron \(i\) ’s activations from that same baseline.
If \(\lvert z_i^l(y)\rvert\) exceeds the OOD threshold \(\theta_{\text{act}}\) , include neuron \(i\) as a possible candidate.
- Add high‐variance neurons (Top‐k Selection)
- Because some neurons have naturally high variance in their activations, include top \(k\) neurons in each layer with highest absolute activations for \(y\) into the initial candidate set.
- If memorization strength is not sufficiently reduced, incrementally increase \(k\) , starting from \(k=0\) .
- Deactivate & evaluate memorization strength
- Deactivate the current set of candidate neurons.
- Check if the memorization strength (via SSIM, compared to \(\tau_{\text{mem}}\) ) has improved.
- Iterate
- If memorization strength is still above the target \(\tau_{\text{mem}}\) , lower the OOD threshold \(\theta_{\text{act}}\) and increase \(k\) , gather new candidates, and repeat the steps 3-4.
Refinement of the Candidate Set
Filter out false positives from the candidate set by systematically testing whether reactivating these neurons restores memorization.
- Initialize the Refinement Set
- Start with the refined set \(S_{\text{refined}}\) set to all initially selected candidate neurons: \(S_{\text{refined}} = S_{\text{initial}}\) .
- Layer-Wise Reactivation
- Group the candidate neurons in each cross-attention layer \(l\) .
- Then, one layer at a time, they re-activate that layer’s candidate neurons \(S_{\text{refined}}^{l}\) (while keeping all other layers’ neurons deactivated) and measure the memorization score SSIM.
- If reactivating those neurons from layer \(l\) does not push the SSIM score above the memorization threshold \(\tau_{\text{mem}}\) , those layer- \(l\) neurons, \(S_{\text{refined}}^{l}\) , are removed from \(S_{\text{refined}}\) .
- Neuron-Wise Reactivation
- Having pruned whole layers that do not affect memorization, then test each remaining neuron individually.
- Re-activate exactly one neuron at a time (with all other neurons in \(S_{\text{refined}}\) still inactive) to see whether it singlehandedly elevates memorization beyond \(\tau_{\text{mem}}\) .
- Neurons failing to raise memorization above that threshold are discarded.
- Final Memorization Set
- After this two-stage refinement, any neuron still remaining in \(S_{\text{refined}}\) is deemed genuinely responsible for memorization. The authors call this final subset: \(S_{\text{final}}\) .
Source
BibTeX:
1 2 3 4 5 6 7 8
@article{hintersdorf2024finding, title={Finding nemo: Localizing neurons responsible for memorization in diffusion models}, author={Hintersdorf, Dominik and Struppek, Lukas and Kersting, Kristian and Dziedzic, Adam and Boenisch, Franziska}, journal={Advances in Neural Information Processing Systems}, volume={37}, pages={88236--88278}, year={2024} }