[Brief Review] Unified Concept Editing in Diffusion Models
Takeaway Summary
Keywords: unified-concept editing, text-to-image, closed-from editing, concept to preserve, safety issues, a pair of source-destination inputs, debiasing, erasing, moderation, cross-attention, single-pass edit
✅ Untargeted Concept Preservation: By incorporating preservation concept embeddings and the concept-preserving term \(\sum_{c_j \in P} \left\| W c_j - W^{\text{old}} c_j \right\|_2^2\) into the objective function, Unified Concept Editing (UCE) effectively directs concept editing, preserving original knowledge of untargeted objectives.
✅ Efficient One-step Update Editing: UCE updates model parameters efficiently in a single step using the closed-form solution \(W = \left( \sum_{c_i \in E} v_i^* c_i^T + \sum_{c_j \in P} W^{\text{old}} c_j c_j^T \right) \left( \sum_{c_i \in E} c_i c_i^T + \sum_{c_j \in P} c_j c_j^T \right)^{-1}\) . This enables fast editing, typically taking less than one minute, without the need for costly fine-tuning or retraining.
✅ Simultaneous Editing of Multiple Concepts: UCE’s unified one-step update method supports simultaneous editing across multiple tasks. Given a list of multiple concepts to edit (including styles, professions, and content categories) along with their desired new embeddings \(c_i^*\) , and any concepts intended for preservation \(c_j\) , UCE efficiently executes all edits in a single pass using the closed-form solution.
Brief Review
Overview
Summary: UCE is a unified model-editing approach for text-to-image models that tackles various safety issues within a single framework. By incorporating concept preservation, it extends the existing TIME [Orgad et al.,2023] method, enabling finer-grained edits while preventing unwanted changes. UCE provides a single-step update derived from a closed-form solution, allowing simultaneous editing for multiple tasks such as erasure, debiasing, and moderation. Applying this method to critical safety concerns—like copyright infringement, offensive content, and social biases—promotes the development of more socially responsible generative models.
- Task: Concept editing in text-to-image models
- Goal: Edit text-to-image models to address various safety issues, such as bias, copyright infringement, and offensive content within a single formulation.
- Existing Problems:
- Safety issues have limited the deployment suitability of text-to-image models.
- Various safety concerns, such as bias, copyright infringement, and offensive content, have traditionally been treated as distinct problems, each requiring separate solutions.
- Contributions:
- Propose Unified Concept Editing (UCE), a unified model-editing approach designed to address various safety issues through a single formulation.
- The proposed UCE can mitigate multifaceted gender, racial, and other biases simultaneously while maintaining the model’s original capabilities.
- The proposed UCE is scalable, enabling the modification of hundreds of concepts in a single step using a closed-form solution, eliminating the need for costly retraining.
- The proposed UCE shows superior performance in real-world cases.
- The proposed UCE marks a significant progress in democratizing access to ethical and socially-responsible generative models.
Background
Text-to-Image Concept Editing Problem Definition
- The attention modules within diffusion models follow the QKV (Query-Key-Value) structure, where queries originate from the image space, while keys and values are derived from the text embeddings.
- The focus of this paper centers on the linear layers \(W_k\) and \(W_v\) , responsible for projecting text embeddings.
- Basic symbols
- \(c_i\) : text embedding
- \(k_i = W_k c_i\) : key
- \(v_i = W_v c_i\) : value
- \(q_i\) : a query that represents the visual features of the current intermediate image.
An attention map that aligns relevant text and image regions
\[\mathcal{A} \propto \text{softmax}(q_i k_i^T)\]- indicates the relevance between each text token and visual feature.
The cross-attention output
\[\mathcal{O} = \mathcal{A} v_i\]- The cross-attention is the mechanism that links the text and image information and responsible for assigning visual meaning to text tokens.
- The cross-attention output \(\mathcal{O}\) is propagated through the remaining layers of the diffusion U-Net.
TIME [Orgad et al., 2023]
- Implicit assumptions: any visual features that a model assumes about objects in an under-specified prompt
- A pair of source-destination inputs:
- a “source” under-specified prompt for which the model makes an implicit assumption (e.g., “a pack of roses”).
- a “destination” prompt that describes the same setting, but with a specified desired attribute (”a pack of blue roses”).
- TIME updates the projection matrices \(W_k\) and \(W_v\) , to bring the source prompt embedding closer to the destination embedding.
- This aligns the textual concepts such that the model no longer makes the implicit assumption.
The objective function to be optimized:
\[\min_W \sum_{i=0}^{m} \lVert W c_i - \underbrace{v_i^*}_{W^{\text{old}} c_i^*} \rVert_2^2 + \lambda \left\| W - W^{\text{old}} \right\|_F^2\]Its closed-form global minimum solution:
\[W = \left( \sum_{i=0}^{m} v_i^* c_i^T + \lambda W^{\text{old}} \right) \left( \sum_{i=0}^{m} c_i c_i^T + \lambda \mathbb{I} \right)^{-1}\]- \(\sum_{i=0}^{m} c_i c_i^T\) is the covariance of the concept text embeddings being edited.
- In this paper, authors interpret \(\lambda \mathbb{I}\) of TIME as matching the covariance of the large encyclopedia of concept embeddings in the diffusion model’s vocabulary. This implies that it applies uniform regularization across all directions. The identity-based term acts as a constraint, preventing the updated weight matrix from deviating excessively in any single dimension by imposing a uniform ridge penalty.
- Limitation of TIME formulation:
- It risks interference with surrounding concepts when editing a particular concept.
- Its regularization term, designed to prevent excessively radical changes, is general and thus affects all vector representations equally.
Methods
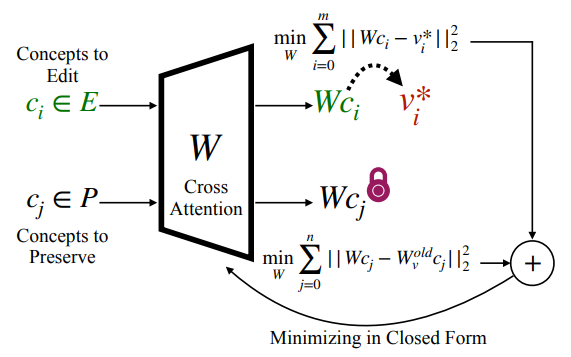
The objective function to be optimized:
\[\min_W \sum_{c_i \in E} \left\| W c_i - v_i^* \right\|_2^2 + \sum_{c_j \in P} \left\| W c_j - W^{\text{old}} c_j \right\|_2^2\]- The goal of the objective function is to find a matrix \(W\) that moves the edited concepts \(c_i\) toward their new target \(v_i^*\), while leaving the preserved concepts \(c_j\) as close as possible to their old outputs \(W^{\text{old}} c_j\) .
- \(W\) : The new linear projection matrix being solved for.
- \(W^{\text{old}}\) : The original (pretrained) weight matrix, from which we are making modifications.
- \(c_i \in E\) : The concept embeddings that must be edited.
- \(v_i^{*} = W_{v}^{\text{old}} c_{i^*}\) : The target values for concept \(c_i \in E\) .
- \(c_j \in P\) : The concept embeddings that must be preserved.
- \(\left\| W c_i - v_i^* \right\|_2^2\) : The squared Euclidean distance enforcing the “edit” objective.
- \(\left\| W c_j - W^{\text{old}} c_j \right\|_2^2\) : The squared Euclidean distance enforcing the “preservation” objective.
The closed-form global minimum solution for the objective function:
\[W = \left( \sum_{c_i \in E} v_i^* c_i^T + \sum_{c_j \in P} W^{\text{old}} c_j c_j^T \right) \left( \sum_{c_i \in E} c_i c_i^T + \sum_{c_j \in P} c_j c_j^T \right)^{-1}\]- While \(\lambda \mathbb{I}\) of TIME imposes uniform regularization across all directions, UCE can preserve specific concepts \(c_j\) exactly as they were.
- Erasing
To erase a concept \(c_i\) (e.g., Vincent van Gogh), modify the weights so that the target output \(v_i\) aligns with a different concept \(c_*\) (e.g., art):
\[v_i^* \gets W^{\text{old}} c_*\]- This updates the weights such that the output no longer reflects concept \(c_i\) .
- Debiasing
- Goal: To debias a concept \(c_i\) (e.g., “doctor”) across attributes \(a_1, a_2, …, a_p\) (e.g., “white”, “asian”, “black”, ..), we want the concept with evenly distributed attributes.
Solution: Adjusting the magnitude of \(v_i\) along the directions of \(v_{a_1}, v_{a_2}, …, v_{a_p}\) , where \(v_{a_i} = W^{\text{old}}a_i\) :
\[v_i^* \gets W^{\text{old}} \left[ c_i + \alpha_1 a_1 + \alpha_2 a_2 + \dots + \alpha_p a_p \right]\]- The constants \(\alpha_i\) are chosen such that the diffusion model generates the concept with any desired probability for each attribute.
Algorithm

- Moderation
To moderate concept \(c_i\) (e.g., “nudity”), set the target output \(v_i^*\) to align with an unconditional prompt \(c_0\) (e.g., “ ”):
\[v_i^* \gets W^{\text{old}} c_0\]- This replaces the output for \(c_i\) with a more generic, unconditional output \(c_0\) , moderating the model’s response by reducing extreme attributes of that concept.
- Differences from TIME
- Targeted Preservation
- TIME: A single “global” anchor \(\lVert W - W^{\text{old}} \rVert\) for all directions not explicitly edited.
- UCE: Explicitly maintains selected tokens \(c_j \in P\) exactly as the original \(W^{\text{old}} c_j\) . This typically leads to less interference on unrelated concepts.
- Scaling to Multiple Concepts
- TIME: Well suited to editing one or a few attributes. Larger edits can risk overwriting more aspects of \(W^{\text{old}}\) .
- UCE: Handles many simultaneous edits (erasure, moderation, debiasing) by simply adding more terms in the set \(E\) and carefully preserving a set \(P\) .
- Customization
- TIME: The user mainly controls \(\lambda\) and the new token embeddings \(c_i^{*}\) .
- UCE: The user can also specify exactly which tokens go untouched, how strongly they remain untouched, and which tokens get re‐mapped to new embeddings.
Thus, UCE generalizes TIME by allowing finer‐grained control over which concepts get altered and which remain unchanged, all within the same closed‐form editing framework.
- Targeted Preservation
- Properties
- General, thus applicable to any linear projection layer.
- A fast and practical way to control model behavior post-training, filling the gaps where data curation might fall short.
- A closed-form parameter editing method that enables the application of hundreds of editorial modifications within a single text-to-image synthesis model while preserving the generative quality of the model for unedited concepts.
- Designed to enable many simultaneous edits, including erasing, moderating, or debiasing a concept, to be applied at once.
- Allow the editor to explicitly specify the distribution of concepts that should not be modified.
- Introduce a new, scalable debiasing approach.
- Superior performance both in individual edits within each editing category and in its ability to scale to multiple simultaneous edits, while minimizing interference with unedited concepts.
Limitations & Challenges
- Compounding biases problem:
- When debiasing across multiple attributes, inter dependencies construct compounding biases, implicating the need for joint attribute consideration.
- Example:
- Suppose the model already tends to depict “doctor” as male (gender bias) and White (racial bias).
- If you only try to remove the gender bias—making “doctor” equally male/female—but ignore the model’s racial skew, it could inadvertently reinforce the model’s existing over‐representation of White doctors.
- Hence, multiple biases can “compound”: solving one in isolation might amplify another, whereas a truly fair outcome requires simultaneously rebalancing both gender and race.
- Word-level biases in prompts
- There are implicit biasing elements that sound technically neutral but result in biased outcomes.
- Example:
- Non-gendered phrases like “successful person” become predominantly male (88% of 100) versus the gender-balanced “person” (50% male of 100), illustrating how subtle cues carry biases.
- The critical mass of artist styles:
- In artistic style erasure, excessive erasure damages the important visual priors learned during pretraining.
Source
BibTeX:
1 2 3 4 5 6 7
@inproceedings{gandikota2024unified, title={Unified concept editing in diffusion models}, author={Gandikota, Rohit and Orgad, Hadas and Belinkov, Yonatan and Materzy{\'n}ska, Joanna and Bau, David}, booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, pages={5111--5120}, year={2024} }