[Brief Review] A Holistic Approach to Undesired Content Detection in the Real World
Warning: The reviewed paper may contain content related to racism, sexuality, or other potentially harmful language.
Takeaway Summary
✅ The proposed taxonomy of undesired content consists of five top-level categories (Sexual, Hateful, Violence, Self-harm, and Harassment) along with a spectrum of subcategories. This taxonomy also covers acceptable (non-undesired) cases, such as contextually appropriate references made for commentary.
✅ The undesired-content moderation system proposed for production data comprises five key components:
- Data Selection and Active Learning,
- Labeling and Quality Control
- Synthetic Data
- Domain-Adversarial Training
- Model Probing.
✅ The presented key findings are as follows:
- Detailed instructions and rigorous quality control are essential to ensure high-quality data.
- Implementing active learning is critical.
- Public datasets should be used with caution.
- Imbalanced training data may cause the model to generalize incorrectly.
- Mistakes in the data are inevitable and must be proactively managed.
Brief Review
Overview
Summary: This paper proposes a holistic and pratical natural language system to moderate undesired content in the real world. Motivated by the lack of widely agreed-upon categorization for undesired content, it first designs a broadly applicable content taxonomy for undesired content. The proposed taxonomy consists of five top-level categories (Sexual, Hateful, Violence, Self-harm, and Harassment) with a spectrum of subcategories, covering the acceptable (not undesired) cases, such as contextualized references for commentary. Next, it proposes an undesired content moderation system that consists of the following 5 components:
- Data Selection and Active Learning: incorporate production data into the training set by handing the most informative or suspicious samples for labeling
- Labeling and Quality Control: improve data quality and correctness of labels by designing detailed definitions and mutually exclusive categories or subcategories and hosting regular calibration sessions to review ambiguous edge cases and instances.
- Synthetic Data: Use synthetic data to improve model performance on rare categories and to mitiage counterfatucal bias towards certain demographic attributes.
- Domain Adversarial Training: Mitigate distribution shift problem between the training public NLP datasets and the production traffic, by encouraging the model to learn domain invariant representations via Wassesetin Distance Guided Domain Adverasrial Training (WDAT).
- Model Probing: Make sure that the models perform as expected by inspecting them by key tokens probing and human-involved red-teaming.
Based on the experiments, it shows the following important finding related to contents moderation:
- Detailed instructions and quality control are needed to ensure data quality.
- Active learning is a necessity.
- Use public datasets with care.
- Imbalanced training data can lead to incorrect generalization.
- Mistakes in data will happen and need to be managed
- Task: A practical and general natual language classification system for real-world contents moderation.
- Goal: To detect a broad set of undesired contents including sexual content, hateful content, violence, self-harm, and harrassment.
- Existing Problems: Challenges in detecting undesired content
- There is no clearly and widely agreed-upon categorization of undesired content.
- A practical moderation system needs to process real-world traffic. Thus, a model bootstrapped from public data or academic datasets would not work well.
- It is rare to encounter certain categories of undesired content in real world settings.
- Noteworthy Findings: about Contents Moderation
- Detailed instructions and quality control are needed to ensure data quality.
- Active learning is a necessity.
- Use public datasets with care.
- Imbalanced training data can lead to incorrect generalization.
- Mistakes in data will happen and need to be managed.
- Contributions:
- Propose a holistic approach to building a reliable and robust undesired content detection model for real-world applications, handling the rarely observed cases.
- Design a broadly applicable content taxonomy for undesired content.
- Provide an analysis on critical factors for content moderation system.
Methods
Taxnomy for Undesired Content
The proposed taxonomy consists of five top-level categories with a spectrum of subcategories. It is noteworthy that the taxonomy also includes subcategories for acceptable (not undesired) cases, such as contextualized references for commentary.
- Sexual:
- Undesired
- minor
- could be illegal
- erotic but not illegal,
- Not Undesired
- non-erotic or contextualized
- Undesired
- Hateful:
- Undesired
- calling for violence of threatening
- derogatory stereotypes or support for hateful statements
- Not Undesired
- neutral statement referring to group identity
- contextualized hate speech, e.g., for the purpose of a commentary
- Undesired
- Violence (support for physical violence)
- Undesired
- extremely graphic violence
- threats of support f or violence
- Not Undesired
- neutral depictions of contextualized violence
- Undesired
- SHL: Self-harm
- HR: Harassment
Undesired Content Moderation
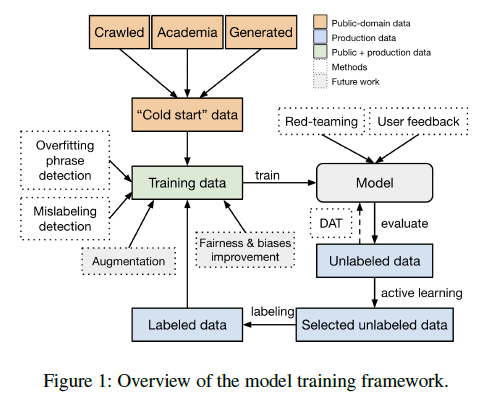
- Data Selection and Active Learning
- Incorporate production data into the training set via a three-stage procedure:
- Randomly select a large volume of production data with any potential personally identifiable information (PII) masked.
- Run a simple active learning strategy to select a subset of most valuable samples to be labeled out for the random samples extracted in stage one.
- All the samples selected by different active learning strategies are aggregated and re-weighted based on the statistics of certain metadata ssociated with it.
- Incorporate production data into the training set via a three-stage procedure:
- Labeling and Quality Control
- Aim to improve data quality and correctness of labels.
- Design detailed definitions and mutually exclusive categories or subcategories
- Host regular calibration sessions to review ambiguous edge cases and instances
- When discrepancies arise, annotator training is refined, and borderline rules are clarified.
- Synthetic Data
- Use synthetic data to improve model performance on rare categories and to mitiage counterfatucal bias towards certain demographic attributes.
- Particularly helpful when there is little to no initial data (”cold start”) or when there are not enough undesired samples in the production traffic.
- Few-shot data uses limited real examples to guide generation, while zero-shot relies on carefully designed prompt templates.
- By curtaing a synthetic dataset with templates that tend to lead to hateful predictions, mitigate counterfactual bias.
- Find that large of amount of noisy data does not help.
- Domain Adversarial Training
- By applying Wassesetin Distance Guided Domain Adverasrial Training (WDAT), encourage the model to learn domain invariant representations, in order to mitigate distribution shift problem between the training public NLP datasets and the production traffic.
- Model Probing
- Tool-assisted model probing: Key tokens probing
- Verify whether the modle makes predictions based on correct features by input reduction technique where tokens are greedily removed until the prediction drops below 0.8.
- Human-in-the-loop red-teaming
- Uncover any unexpected model weakness beyond the test dataset by internal red-teaming before releasing.
- Tool-assisted model probing: Key tokens probing
Key Terms
| Keyword | Explanation | Roles in the paper |
|---|---|---|
| Undesired Content | Text deemed harmful, restricted, or disallowed (e.g., hateful, sexual, violent). | The main target for classification; the entire system is designed to detect and manage this content in real-world applications. |
| Taxonomy | A structured set of categories and subcategories for labeling content. | Defines the classification space (e.g., Sexual, Hate, Violence, etc.) and their subtypes, ensuring a consistent framework for annotators and model training. |
| Sexual Content (S) | One of the paper’s top-level categories covering sexual or erotic content. | Illustrates how the system detects explicit sexual content or references that may be disallowed in certain contexts. |
| Hate Content (H) | Content that is threatening, insulting, or demeaning toward specific protected groups. | A core category with subcategories for identifying hateful or harassing statements related to protected attributes. |
| Violence Content (V) | Content describing or advocating physical harm or threats. | Another major category of undesired content that the model learns to detect, including threats or calls to violence. |
| Harassment Content (HR) | Content aimed at tormenting or targeting specific individuals or groups with hostility. | Distinct from hate, it focuses on personal harassment or bullying. |
| Self-Harm Content (SH) | Content describing self-injury or suicidal ideation. | Special category requiring intervention or caution; the system must identify it accurately for possible self-harm prevention. |
| Subcategories (S1, S2, S3, H1, H2, etc.) | More fine-grained levels under each top-level category (e.g., S1 might be mild sexual content, S2 more explicit). | Enables nuanced classification and helps the model capture different severities or contexts. |
| Annotation Guidelines | Detailed instructions provided to human labelers to categorize text consistently. | Ensures labeling quality and consistency across a large pool of annotators, a critical requirement for reliable model training. |
| Active Learning | Iterative strategy where the model suggests the most informative or uncertain samples for labeling. | Addresses the rarity of undesired content by prioritizing labeling on likely positive examples or ambiguous cases. |
| Production Data | Text from real user inputs in a live environment. | Key source of authentic, up-to-date samples reflecting actual usage patterns and emergent forms of undesired content. |
| Data Distribution Shift | Mismatch between training datasets (public) and real-world production texts. | Motivates techniques like domain adversarial training to adapt the model and avoid performance degradation. |
| Domain Adversarial Training (DAT) | A training method that encourages the model to learn domain-invariant features, reducing domain mismatch. | Improves generalization from public data to production data where text style and topics differ. |
| Zero-Shot Data | Synthetic examples generated by prompting a model (e.g., GPT-3) with instructions for a category (like self-harm), without prior examples. | Helps cover label categories with few real samples by creating artificial yet domain-relevant content. |
| Synthetic Data | Artificially generated text samples designed to supplement real labeled data. | Expands the dataset to include niche or corner cases (e.g., explicit threats, self-harm scenarios), improving classifier robustness. |
| Corner Cases | Uncommon yet significant examples that deviate from typical patterns. | Often missed in random sampling but crucial for detecting subtle or rare forms of undesired content. |
| Model Probing | Techniques (e.g., token removal, input manipulation) to investigate how a model arrives at predictions. | Uncovers hidden biases, spurious correlations, or overreliance on keywords in the classifier. |
| Human Red-Teaming | Human-led attempts to break or fool the model, often via adversarial or tricky inputs. | Helps discover blind spots or vulnerabilities not obvious during routine development. |
| Cold Start Data | The limited initial dataset available before a system is fully operational. | Kickstarts the training pipeline, often enhanced with synthetic data to mitigate early distribution gaps. |
| Calibration Sessions | Meetings or procedures where annotators review borderline examples to align on correct guidelines. | Reduces confusion about category boundaries and increases inter-annotator agreement. |
| Wasserstein Distance | A measure used in domain adversarial training to compare data distributions. | Guides the model to learn from public and production data in a way that reduces domain-related discrepancies. |
| AUPRC (Area Under the Precision-Recall Curve) | A metric evaluating how well the model catches positive cases (precision) at various recall levels. | The paper’s primary performance measure, especially useful for imbalanced classification tasks. |
| Production Readiness | The state of the system being robust enough to handle real-world traffic at scale. | A key aim; the methodology must adapt to new content types and handle large volumes without severe performance drops. |
Source
BibTeX:
1 2 3 4 5 6 7 8 9
@inproceedings{markov2023holistic, title={A holistic approach to undesired content detection in the real world}, author={Markov, Todor and Zhang, Chong and Agarwal, Sandhini and Nekoul, Florentine Eloundou and Lee, Theodore and Adler, Steven and Jiang, Angela and Weng, Lilian}, booktitle={Proceedings of the AAAI Conference on Artificial Intelligence}, volume={37}, number={12}, pages={15009--15018}, year={2023} }